







体验产品体验更多产品 >






“目前大模型并没有真正理解自然语言,仅仅是表象上产生了文字。”
当下大模型发展如火如荼,热度不减,拥抱AI、推进智能化转型,成为企业发展中亟待解决的问题。
8月9日,致远互联第15届用户大会在武汉举行,聚焦协同管理行业、围绕“AI-COP让组织智能进化”的主题,学界、企业界人士展开讨论与交流。
复旦大学计算与智能创新学院教授、复旦大学眸思大模型项目首席科学家、上海市智能信息处理重点实验室副主任张奇在大会上表示:“目前大模型还处于记忆层面,并不能真正去理解自然语言。它仅仅是表象上产生了文字。”

作为在自然语言处理领域深耕20余年的行业“老兵”,张奇言简意赅解答了大模型发展中的两个关键问题:一是大模型问什么落地难?二是大模型适用于什么方面,如何才能落地?
大模型为什么落地难
全数据驱动的大模型,实现“类人推理”面临巨大挑战。
随着大模型的开源,用户数剧增,大模型训练的数据库越来越庞大。但这并不意味着,大模型学会了理解,具备了“类人推理”的能力。问题的关键在于大模型的能力边界,这也是是学界与业界不断研究探索的问题。
大模型的学习方式与人类的学习方式是完全不同的两种范式。张奇认为,人类的学习模式是层层递进的,在这个学习过程中人类培养起了学习能力,具备了独立思考和推理判断的能力。但当前大模型的“学习”是模块式的,其学习掌握的内容来自训练过程中相关模块数据的输入,这一过程并不能助其建构起推理能力。
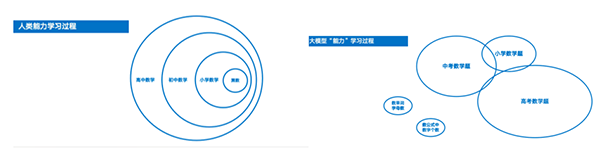
大模型习得的是一个个分离的“圆圈”。张奇解释称,“如果做可控的实验,在预训练阶段把小学应用题全部去掉,放入大量高考题。结果就是该大模型高考可以考到145分,小学应用题得分却很低。“
在训练过程中可以发现,目前大模型在解答高考题方面,其分数能够达到985院校的分数录取要求。但如果对简单题目做“变形”处理,大模型给出的答案准确率也会下降很多。

举例来看,在一道小学数学题目中添加一个简单的、与解题无关的条件后,GPT-o1-mini模型给出的答案从开始的90多分下降了17.5分。而更小一点的模型结果则从80多分下降到不足20分,这样的答案差距仅仅是因为在题目中添加了一个不相关的条件。
因此,张奇认为:“现在大模型依然是统计记忆学习的范式,所以它不能建立因果的关联。”
除此之外对大模型能力边界的测试还包括这样一则案例,即“将56个1相加,在其中穿插两个11,要求大模型计算答案”,结果大模型思考10分钟后,并未给出准确答案。
张奇认为大模型相较于小模型有四项不同的能力,包括长上下文建模和多任务学习能力。因为此前,小模型最多可以做512个token、大约700个汉字,且小模型只能处理单一任务,所以大模型要实现的是长上下文建模和多任务学习能力,才能体现出它的进步之处。此外,大模型还需要具备多任务间的跨语言迁移能力和文本生成能力。以上四项能力构成了大模型落地的关键。
小场景+大数据=落地效果好
大模型落地的关键是选择合适的应用场景。
德勤此前发布的一则数据图表显示,AI最适宜帮助人们完成的是“人类能够便捷高效的作出判断的”工作,例如创作一幅图画或者撰写一个笑话等。张奇说,“既代替了大量的人工,又使输出的结果非常容易判定,扫一眼就知道结果,这样的场景是非常适合大模型完成的。”
但当前对大模型任务执行结果的验证也成为束缚其应用场景拓展的一大因素。以船厂图纸的审核为例,通过大模型审核图纸重的错误过程中,“模型做的再好,也只能做到95分。”张奇称。这意味着,需要人力对大模型执行结果进行验证和审核。所以,从这个意义上来看,大模型任务完成达到95分亦或是60分,已经不再有区别。因为人力审核校验成为难以避免的环节。
因此,无论是大模型还是小模型,其只是一种工具,找到适配的场景才是大模型落地的关键。基于该判断,场景越小,数据越多,则AI的任务执行结果会越好。
除了找到合适的应用场景,商业价值是大模型落地难以回避的问题。
张奇对此表示,大模型非常容易在很多场景下做到70分,但是做到90分是非常困难的。
因此,不需要神化或拟人化模型,它的本质依然是记忆学习。区别在于,当大模型体量更大的时候,能够完成的任务更多,技术层面需要做的则是根据实际应用场景对模型进行逐项优化。
对于企业而言,2025是争取市场份额的关键节点。张奇表示,企业要积极拥抱AI,找到核心应用场景并实现应用效果的提升,将成为抢占市场份额的重要路径。
大会专题入口:
AI赋能 · 开箱即用 · 无缝协作
百余种业务应用互联互通,无缝衔接
















行业领航 · 深度定制 · 标杆实践
行业专属定制方案,源自TOP企业成功实践












 京公网安备11010802020540号
京公网安备11010802020540号